
Multi DataSource, Load Balancing and Failover
If you have some idea on Data Source, clustering and cluster algorithms then it's very easy for you to understand Multi Data Source.
Let me give you some idea. Data Source is a group of ready to use data base connection which is used to get connections) from database as well as for better performance. Since, all the connection created at server startup ( based on the max connection limit defined ) thus it don't make any overhead on application and application server to get connections dynamically at run time. application pick the connection from data source connection pool, used it and returned back to the pool. certain cases you must heard about connection leaking, it nothing just the connection(s) opened in pool, taken by the application but never returned to the pool. most of times it happened when developers didn't close the pool with proper syntax.
Just like a cluster where we grouped different managed server for high availability, Multi Data Source is also just a group of Data Sources used for high availability to provide load balancing and failover capabilities for JDBC connections.

and like cluster algorithms, there are two algorithms provided with Multi Data Source, First one is round robin, and second one is Failover. as you can understand from the name itself, round robin is just to load balance the load equally between all data sources and Failover is to provide failover capabilities, but during lot's of technical interviews i had taken, i felt the use of Failover is not very clear to majority of guys :), let read below.
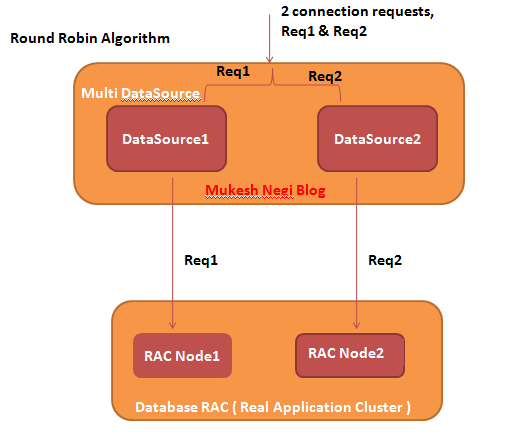
Round Robin Algorithm :
This algo simple load balance the requests between all assigned data sources. As shown in figure below, if your multi data source get 2 requests, then it will equally divert them between both available data source in cyclic manner.
Failover Algorithm :
Data Source or Multi Data Source don't do the failover of current active connections, like if some connection which is server by data source1 got disconnect between processing some requests, then data source or multi data source will not failover request to other available connection, it can be handled at database level.
With this algorithm, doesn't matter how many data sources you have assigned to the multi data source, every request will be serve by the primary first data source in the list until and unless it got failed due to any reason. In that case, if your primary data source got down, all incoming requests will be server by the second data source till first primary data source recovered.

Based on the data source connect string configuration at database listener level, round robin algorithm could be like below

Based on the data source connect string configuration at database listener level, Failover algorithm could be like below

Based on the data source connect string with database service name configuration at database listener level, round robin algorithm could be like below


Nice Explanation
ReplyDeleteSuppose there are 5 req
ReplyDeleteand we have DS1, DS2
Req1 goes to DS1 and rest reqsts goes alternative to both DS.
and if connection bw DS1 breaks, it is obvious that rest rqsts will go to DS2, but what about Req1, would that be lost or handled by DS2 ?????
thanks
That request will break. New connection would create at DB service level if RAC confirgured, but that is the new connection request, original request will lost.
DeleteThank you for taking time and putting this together. god bless you.
ReplyDeleteSatya